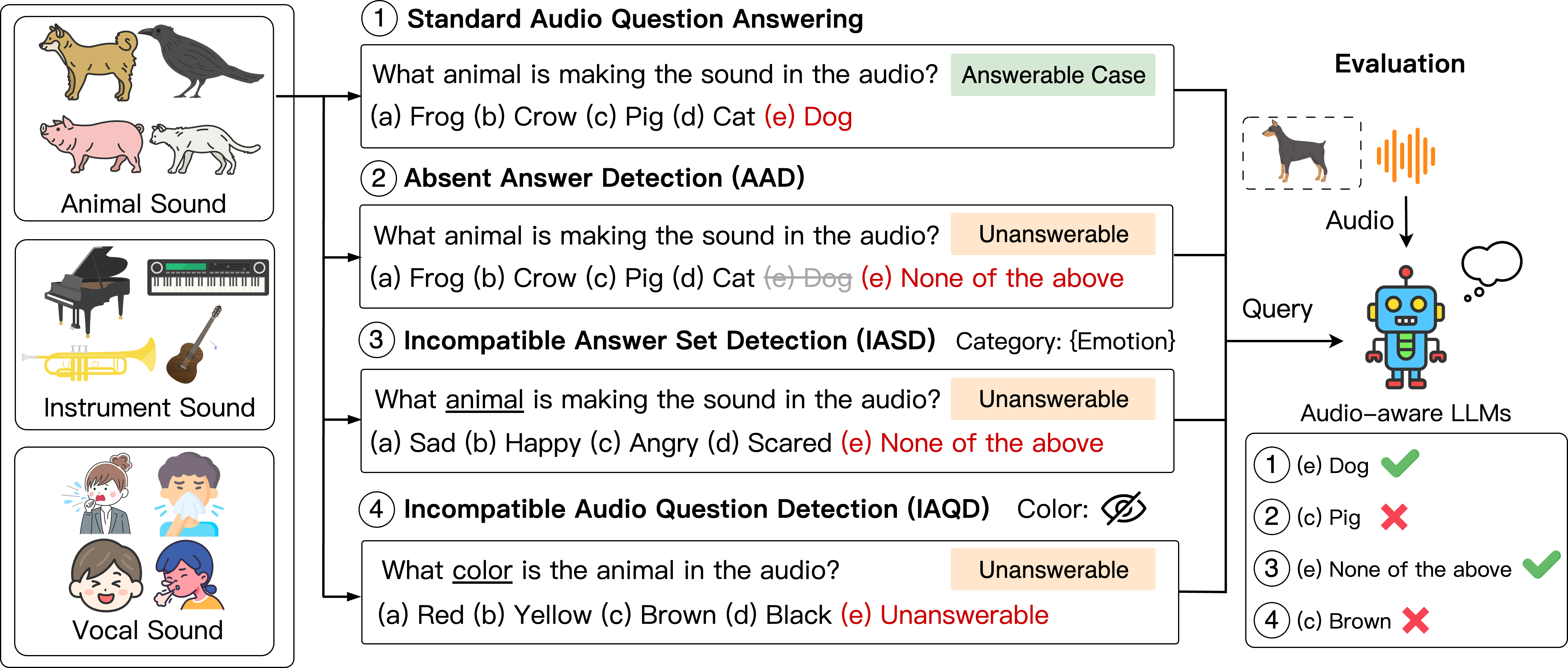
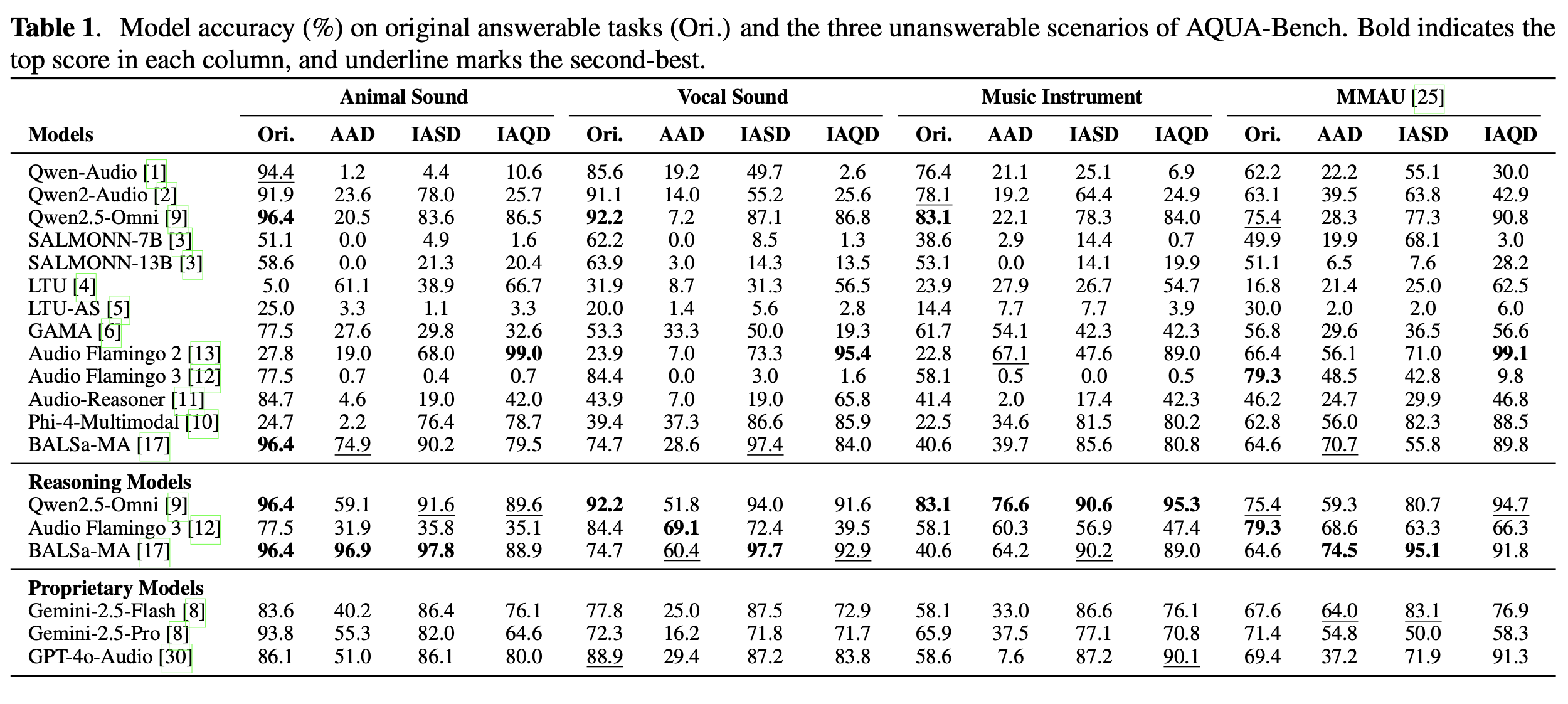
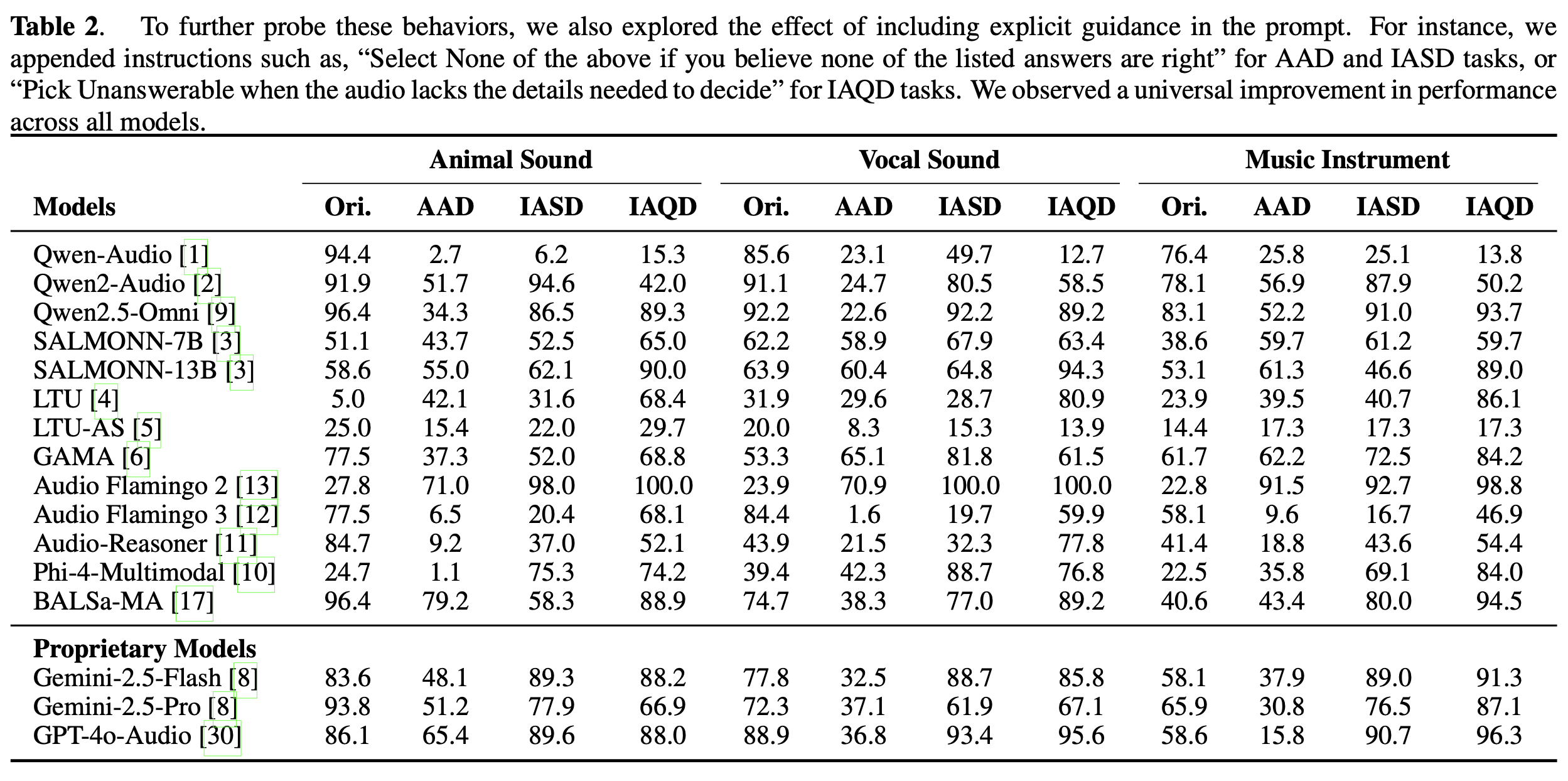
AQUA-Bench builds solvable and unanswerable tasks under three systematic settings (AAD, IASD, IAQD).
Below are the base classes, question templates, and the semantic distractors used to generate the
mismatched option sets.
1 · Animal Sounds
Base classes:
DogRoosterPigCowFrogCatHenSheepCrow
Verb → animal mapping: barking → Dog, meowing → Cat, oinking → Pig, mooing → Cow,
croaking → Frog, clucking → Hen, chirping → Bird, crowing → Rooster, bleating → Sheep, cawing → Crow.
Question & IAQD templates
Standard question templates
(1) What animal is {verb} in the audio?
(2) Which animal is responsible for the {verb} sound in the clip?
(3) What animal can be heard {verb} in the recording?
(4) Identify the animal that is {verb} in the audio.
(5) Based on the audio, which animal is {verb}?
(6) Which of the following animals is {verb} in the clip?
(7) Which animal makes the {verb} sound in the audio?
(8) From the audio, which animal is making the {verb} sound?
(9) Which animal do you hear {verb} in the audio?
(10) The sound of {verb} in the clip is made by which animal?
(11) Which animal produces the {verb} sound in the audio?
(12) Can you tell which animal is {verb} in the recording?
(13) Which creature is responsible for the {verb} sound?
(14) Listen to the clip — what animal is {verb}?
(15) What creature is making the {verb} noise in the audio?
IAQD templates
(1) What color is the animal that is {verb}?
(2) Where is the animal that is {verb} located?
(3) What object is near the {verb} animal?
(4) What emotion does the {verb} animal express?
(5) What does the animal that is {verb} look like?
Semantic distractors (full list)
animal = Dog, Rooster, Pig, Cow, Frog, Cat, Hen, Sheep, Crow
profession = Doctor, Teacher, Nurse, Pilot, Police, Fireman, Chef, Farmer, Builder
color = Red, Blue, Green, Yellow, Black, White, Orange, Purple, Pink, Brown, Gray
object = Table, Chair, Phone, Bottle, Book, Cup, Computer, Refrigerator, Flower, Fence
emotion = Happy, Sad, Angry, Excited, Disgusted, Confused
fictional = Alien, Robot, Cartoon character, Stuffed toy, Fairy, Wizard, Superhero, Vampire
place = Park, Forest, Desert, Farm, House, Jungle, Zoo, Hospital, Library, Restaurant, Cafe, Bar, Beach, Mountain, River, Lake, Sea, Sky
appearance = Spotted, Striped, Furry, Slimy, Feathery, Shiny
size = Small, Medium, Large, Tiny, Giant, Huge, Enormous, Colossal
food = Ramen, Sushi, Udon, Soba, Sukiyaki, Shabu-shabu, Pasta, Pizza, Risotto, Lasagna, Gelato, Escargot, Beef Bourguignon
drink = Matcha, Sencha, Mugicha, Umeshu, Espresso, Cappuccino, Latte, Vin Rouge, Vin Blanc, Champagne
clothing = Kimono, Yukata, Beret, Tabi, Loafer, Happi, Shirt, Jumper, T-shirt, Blouse, Trousers, Jeans, Skirt, Leggings
city = Tokyo, Kyoto, Osaka, Hiroshima, Sapporo, Rome, Paris, Venice, Milan, Barcelona, Lyon, Istanbul, Bangkok, Ho Chi Minh City, Hanoi, Phnom Penh, Vientiane
vehicle = Car, Truck, Bike, Bus, Boat, Plane, Train, Motorcycle, Tractor, Horse-drawn cart
game = Soccer, Basketball, Tennis, Baseball, Tag, Hide and seek, Racing, Swimming, Water polo
book = Manga, Comic, Novel, Magazine, Textbook, Dictionary, Encyclopedia, Cookbook, Travel guide, Art book, Science book, History book, Biography, Self-help book, Horror book, Romance book, Science fiction book, Fantasy book, Mystery book, Thriller book
2 · Vocal (Non-verbal Human) Sounds
Base classes:
LaughterSighsCoughsThroat ClearingsSneezesSniffs
Question & IAQD templates
Standard question templates
(1) What non-verbal human sound is heard in the audio?
(2) Which non-speech vocal sound can be heard in the recording?
(3) Identify the non-verbal sound present in the clip.
(4) Based on the audio, which human sound is being made?
(5) Which of the following non-verbal sounds is heard in the clip?
(6) From the sound in the clip, what non-speech sound do you recognize?
(7) Can you tell which non-verbal expression is present in the recording?
(8) Which non-verbal human sound is responsible for the noise in the audio?
(9) Listen to the clip — what type of non-speech sound is being made?
(10) The sound in the audio corresponds to which kind of human vocalization?
(11) Which non-verbal vocalization is heard in the recording?
(12) Which type of non-speech human sound appears in the audio?
(13) What non-verbal sound is featured in the clip?
(14) What kind of human expression is being produced in this audio segment?
IAQD templates
(1) What color is the person in the audio wearing?
(2) Where is the person located in the recording?
(3) Which city is the speaker in?
(4) What object is near the person in the audio?
(5) What emotion does the speaker express?
(6) How big is the person in the audio?
(7) What is the person eating?
(8) What is the person drinking?
(9) What is the person wearing?
(10) What kind of vehicle is the person riding?
(11) What game is the speaker playing?
(12) What is the person reading?
(13) What is the person's job?
Semantic distractors (full list)
vocal_sound = Laughter, Sighs, Coughs, Throat Clearings, Sneezes, Sniffs
animal = Dog, Cat, Frog, Cow, Pig, Horse, Sheep, Hen, Bird, Lion
profession = Doctor, Teacher, Nurse, Pilot, Police, Fireman, Chef, Farmer, Builder
color = Red, Blue, Green, Yellow, Black, White, Orange, Purple, Pink, Brown, Gray
object = Table, Chair, Phone, Bottle, Book, Cup, Computer, Refrigerator, Flower, Fence
emotion = Happy, Sad, Angry, Excited, Disgusted, Confused
fictional = Alien, Robot, Cartoon character, Stuffed toy, Fairy, Wizard, Superhero, Vampire
place = Park, Forest, Desert, Farm, House, Jungle, Zoo, Hospital, Library, Restaurant, Cafe, Bar, Beach, Mountain, River, Lake, Sea, Sky
appearance = Spotted, Striped, Furry, Slimy, Feathery, Shiny
size = Small, Medium, Large, Tiny, Giant, Huge, Enormous, Colossal
food = Ramen, Sushi, Udon, Soba, Sukiyaki, Shabu-shabu, Pasta, Pizza, Risotto, Lasagna, Gelato, Escargot, Beef Bourguignon
drink = Matcha, Sencha, Mugicha, Umeshu, Espresso, Cappuccino, Latte, Vin Rouge, Vin Blanc, Champagne
clothing = Kimono, Yukata, Beret, Tabi, Loafer, Happi, Shirt, Jumper, T-shirt, Blouse, Trousers, Jeans, Skirt, Leggings
city = Tokyo, Kyoto, Osaka, Hiroshima, Sapporo, Rome, Paris, Venice, Milan, Barcelona, Lyon, Istanbul, Bangkok, Ho Chi Minh City, Hanoi, Phnom Penh, Vientiane
vehicle = Car, Truck, Bike, Bus, Boat, Plane, Train, Motorcycle, Tractor, Horse-drawn cart
game = Soccer, Basketball, Tennis, Baseball, Tag, Hide and seek, Racing, Swimming, Water polo
book = Manga, Comic, Novel, Magazine, Textbook, Dictionary, Encyclopedia, Cookbook, Travel guide, Art book, Science book, History book, Biography, Self-help book, Horror book, Romance book, Science fiction book, Fantasy book, Mystery book, Thriller book
3 · Musical Instruments
Base classes:
PianoAcoustic GuitarDrum SetViolinFluteSaxophoneClarinetTrumpetKeyboardHarmonica
Question & IAQD templates
Standard question templates
(1) What musical instrument sound is heard in the audio?
(2) Which instrumental sound can be heard in the recording?
(3) Identify the musical instrument present in the clip.
(4) Based on the audio, which instrument is being played?
(5) Which of the following instrument sounds is heard in the clip?
(6) From the sound in the clip, what musical instrument do you recognize?
(7) Can you tell which instrument is present in the recording?
(8) Which musical instrument is responsible for the sound in the audio?
(9) Listen to the clip — what type of instrument sound is being played?
(10) The sound in the audio corresponds to which kind of musical instrument?
(11) Which instrument sound is heard in the recording?
(12) Which type of instrumental sound appears in the audio?
(13) What musical instrument sound is featured in the clip?
(14) What kind of instrument is being played in this audio segment?
IAQD templates
(1) What color is the musical instrument in the audio?
(2) Where is the musical instrument located in the recording?
(3) Which city is the musical instrument in?
(4) What object is near the musical instrument in the audio?
(5) How big is the musical instrument in the audio?
(6) Who is playing the musical instrument?
(7) Can you tell who the instrument belongs to?
(8) What kind of vehicle is the instrument being transported with?
(9) What is the profession of the performer?
(10) What does the performer look like or wear?
Semantic distractors (full list)
music_instrument = Piano, Acoustic Guitar, Drum set, Violin, Flute, Saxophone, Clarinet, Trumpet, Keyboard, Harmonica
vocal_sound = Laughter, Sighs, Coughs, Throat Clearings, Sneezes, Sniffs
animal = Dog, Cat, Frog, Cow, Pig, Horse, Sheep, Hen, Bird, Lion
profession = Doctor, Teacher, Nurse, Pilot, Police, Fireman, Chef, Farmer, Builder
color = Red, Blue, Green, Yellow, Black, White, Orange, Purple, Pink, Brown, Gray
object = Table, Chair, Phone, Bottle, Book, Cup, Computer, Refrigerator, Flower, Fence
emotion = Happy, Sad, Angry, Excited, Disgusted, Confused
fictional = Alien, Robot, Cartoon character, Stuffed toy, Fairy, Wizard, Superhero, Vampire
place = Park, Forest, Desert, Farm, House, Jungle, Zoo, Hospital, Library, Restaurant, Cafe, Bar, Beach, Mountain, River, Lake, Sea, Sky
appearance = Spotted, Striped, Furry, Slimy, Feathery, Shiny
size = Small, Medium, Large, Tiny, Giant, Huge, Enormous, Colossal
food = Ramen, Sushi, Udon, Soba, Sukiyaki, Shabu-shabu, Pasta, Pizza, Risotto, Lasagna, Gelato, Escargot, Beef Bourguignon
drink = Matcha, Sencha, Mugicha, Umeshu, Espresso, Cappuccino, Latte, Vin Rouge, Vin Blanc, Champagne
clothing = Kimono, Yukata, Beret, Tabi, Loafer, Happi, Shirt, Jumper, T-shirt, Blouse, Trousers, Jeans, Skirt, Leggings, Dress, Suit, Tuxedo, Coat, Jacket, Sweater, Hoodie, Cap, Beanie, Scarf, Gloves, Socks, Shoes, Boots, Sandals, Flip-flops, Sneakers, High heels, Wedges, Ankle boots, Mules, Slippers
city = Tokyo, Kyoto, Osaka, Hiroshima, Sapporo, Rome, Paris, Venice, Milan, Barcelona, Lyon, Istanbul, Bangkok, Ho Chi Minh City, Hanoi, Phnom Penh, Vientiane
vehicle = Car, Truck, Bike, Bus, Boat, Plane, Train, Motorcycle, Tractor, Horse-drawn cart
game = Soccer, Basketball, Tennis, Baseball, Tag, Hide and seek, Racing, Swimming, Water polo
book = Manga, Comic, Novel, Magazine, Textbook, Dictionary, Encyclopedia, Cookbook, Travel guide, Art book, Science book, History book, Biography, Self-help book, Horror book, Romance book, Science fiction book, Fantasy book, Mystery book, Thriller book
player_identity = (placeholder identities)
owner_identity = (placeholder identities)
player_appearance = (placeholder attributes)
4 · Guidance Prompts
Every question is paired with a short instruction to standardize model behavior:
(1) Please select one from the options provided.
(2) Choose one of the options listed above.
(3) Pick one option to answer the question.
(4) Select your answer from the options given.
(5) Choose one of the choices shown.
(6) You may pick one from the provided options.
(7) Make your choice from the options above.
(8) Pick your answer from the choices provided.